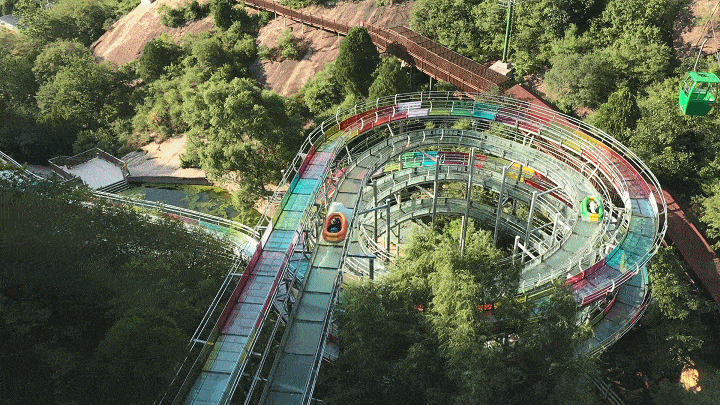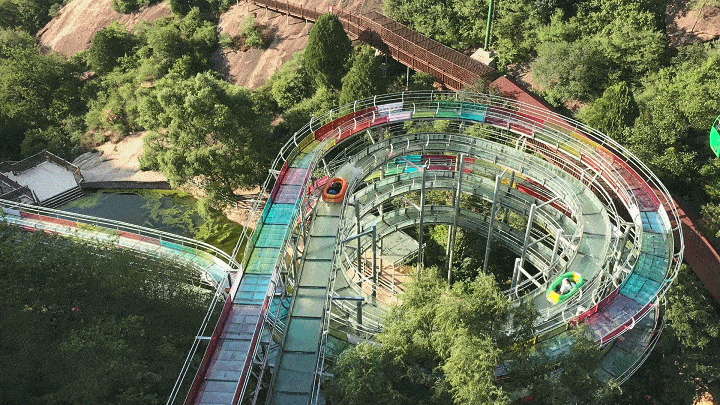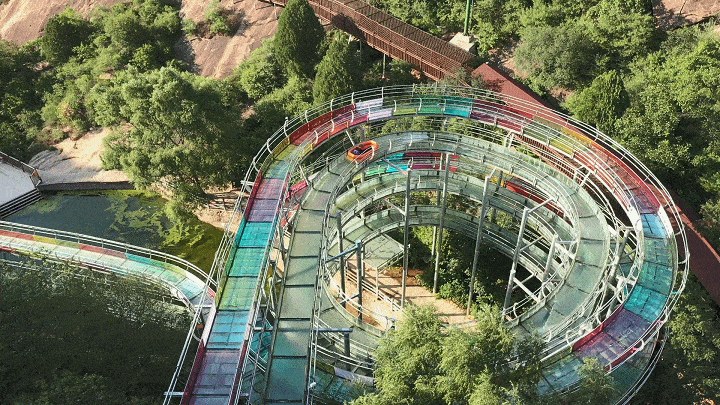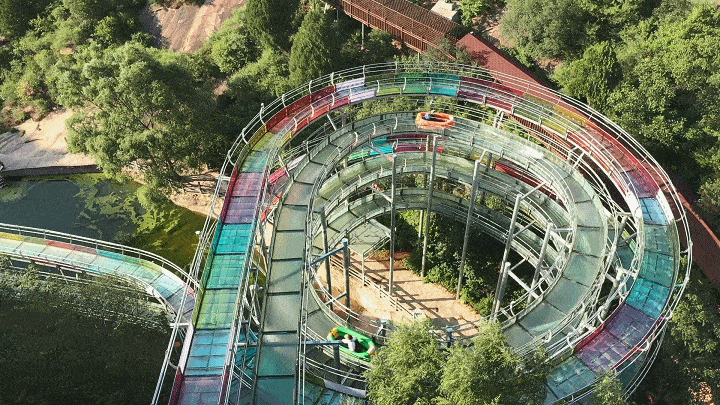(资料图片仅供参考)
微软日前推出语音合成模型NaturalSpeech2,该模型采用潜在扩散式设计,可提供“商业级”语音,歌唱解决方案。在零样本情况下,该模型可以生成具有不同说话人身份、韵律和风格(如唱歌)的语音的能力。且其在零样本条件下生成的语音与语音提示,和真实语音的韵律近乎一致,并在LibriTTS和VCTK测试集上的自然度(以CMOS为度量)与真人语音难以区分。
关键词:
中国名将被吐槽“有些飘”,仍获300万奖金,“一哥”或再创历史
“90后”唐卡画师“接棒”千年技艺
一起去海边吧!甜美泳装【晨夕·小海螺】携夏日缤纷饰品清爽上线!
异动快报:三毛B股(900922)7月28日13点0分触及涨停板
蔚来充电站将禁止“烧油车”使用?蔚来副总:正研究新政策
卫生间地面漏水怎么处理(卫生间地面漏水不刨地怎么处理)
朱吕公路6943号(对于朱吕公路6943号简单介绍)
杭州亚运会集体项目抽签结果出炉
中央财经2台在线直播观看2020(中央财经2台在线直播)
强光下的羊脂白玉
电动自行车停在店门口被盗,民警追踪4天逮住偷车贼
掩耳盗铃之骗得了自己骗不了警方
国家文物局:今年将全力争取“普洱景迈山古茶林文化景观”申遗工作
不完美受害人钟楚曦饰演(钟楚曦是广州花都区人吗)
企业老板如何管理营销团队?
消保委抽检41款宠物视频,2款产品细菌过多,疯狂小狗等六家犬粮表现良好
以中庸之道,精研东方形韵,AEKE更懂东方人
有蔬菜配送公司沪鑫餐饮供应链不用担心每天采购的数量和质量
河南鲁山农信社千万元贷款被曝问题多 第三方土地遭遇解押难
中国著名品牌沃特VOIT亮相2023中华品牌商标博览会莆田鞋展馆
热ྂ冒ྂ烟ྂ了ྂ,快来清凉谷防暑降温吧!
百年老字号祥禾饽饽铺的一次国际化探索
“2022-2023年度中国医药制造业百强”出炉,扬子江药业集团荣登榜首
第十五届中国医药产业发展高峰论坛在哈举办
 (资料图片仅供参考)
(资料图片仅供参考)